Database Content
| Model Name | Total Number | API Link |
|---|---|---|
| Biomarkers | 924 | All Biomarkers |
| Articles | 109 | All Articles |
| Approach Type | 11 | All Experiment Types |
| Fluids used in Assays | 11 | All Fluids |
| Biological Substrates used in Assays | 9 | All Substrates |
| Clinical Study Types | 2 | All Clinical Study Types |
| Indications | 23 | All Indications |
| Cohorts | 52 | All Cohort names |

PTSD Biomarker Database contains a RESTful service documented with the OpenAPI specification. The API can be explored by accessing the first link below where the multiple endpoints to programmatically query the database can be explored. Furthermore, the models and schema of the database are depicted in the second link.
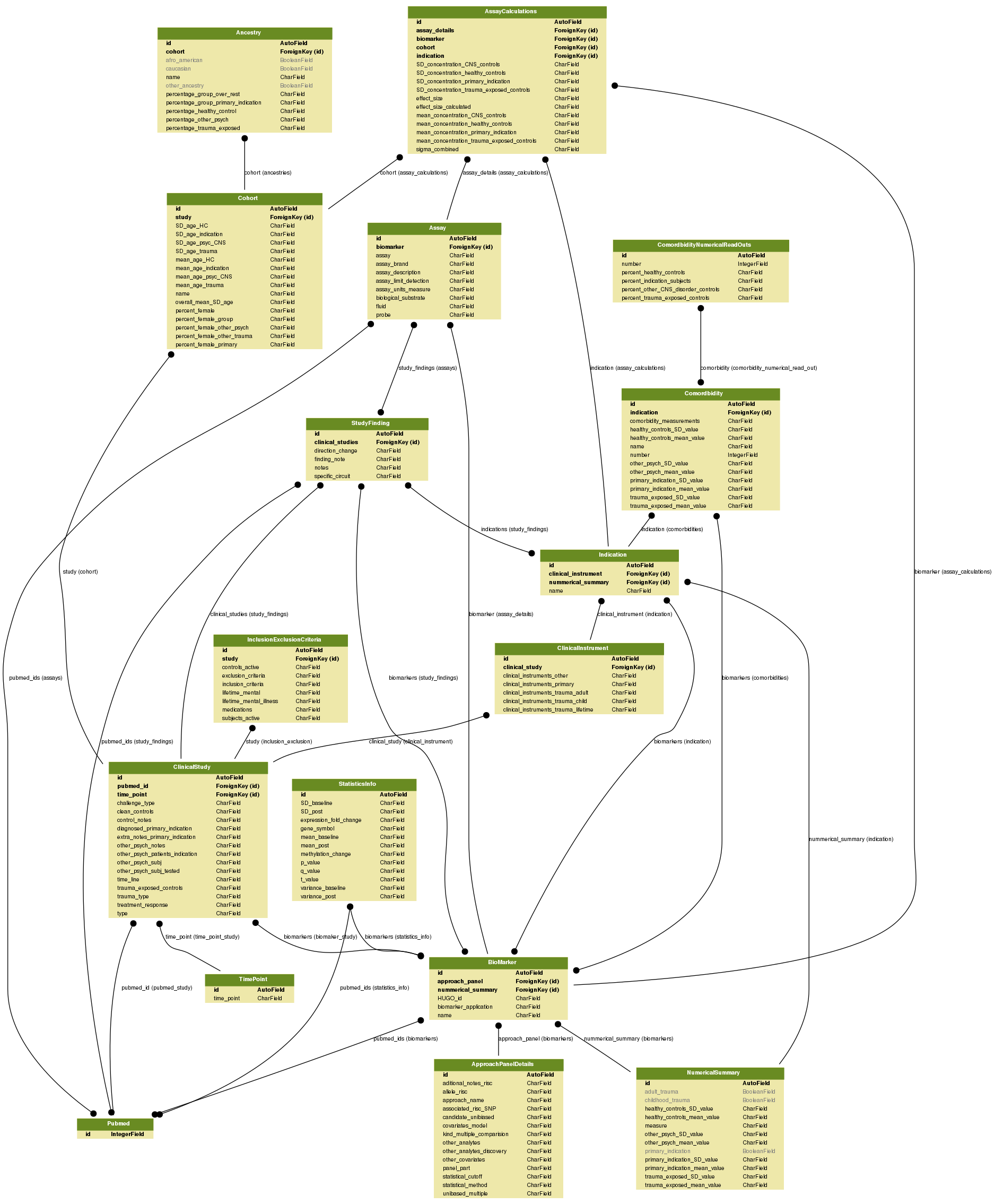{kind=link}
Biomarker Deep Dive Meta-Analysis Paper Selection Methods
This section describes the procedures followed to select the corpora that the PTSD Biomarker Database builds upon
Study Selection
The publications included in the PTSDDB were identified by searching citations in key publications, through field consensus, and conducting a review of published literature according to PRISMA guidelines. For the PRISMA search, PubMed was used to search articles published between January 1985 and December 2017 using a collection of MeSH terms synonyms to PTSD (Supplementary Information). The results from this query were filtered to retain only studies based on PTSD biomarkers, filtering out other type of studies (i.e., reviews, meta-analysis, case studies, opinion pieces, letters, and editorials). Next, a manual inspection was conducted to remove duplicates and articles not written in English. Finally, the resulting corpus was filtered using inclusion and exclusion criteria (Supplementary Information). At this stage of database development, PRISMA searches were deployed for the biomarkers FKBP5 and BDNF.
Data Extraction and Quality Assessment
The biomarker meta-data information contained in the resulting 109 publications was manually extracted and added to a data model template by five independent curators. The spectrum of curated meta-data covers a number of fields, including study design, demographics, study findings, assay information, and statistical methods (Supplementary Information). Ultimately, three rounds of quality control were conducted to ensure the fidelity of the meta-data. In each round of quality control, the meta-data was reviewed by a distinct curator; if inconsistencies were found, curators worked together to reach a consensus.